

こんにちは! Nocky(のっきー)です!
Google Colaboratoryを活用すれば、環境設定することなく今すぐPythonを実行できます。
実施に手を動かして、Pandasを体験してみましょう!
Pandasのインストール
まずはPandasをインストールしましょう!
pip install pandas
pip install numpyGoogle Colaboratoryであれば、インストールされている状態だと思いますが、インストールされてないようであれば下記でインストールしましょう。
!pip install pandas
!pip install numpyインストールが完了したら、利用できるようにインポートします。
import pandas as pd
import numpy as npNumpyをインポートする理由はのちに乱数を発生させて、Pandasの基本操作をするためのデータとして活用するためです。
【頻出】Pandasの2つの主要なデータ構造
1次元のデータをSeries()で作成
まずPandasで1次元のデータを作ってみましょう!1次元のデータを作るためにはSeries()を使います。
リスト型にデータ入れて次のように書きます。
import numpy as np
import pandas as pd
s = pd.Series([1, 2, 3, 4 ,5, np.nan ])
s5つのデータが入っているのがわかりますね。
[shift]+[return]キーで実行して、sを表示します。
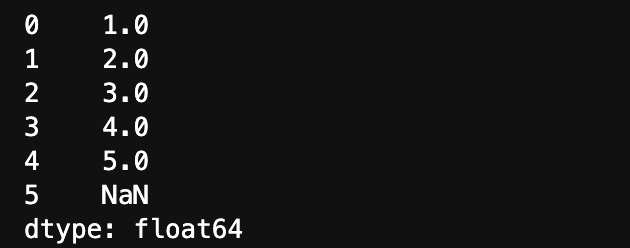
入力したデータとそのインデックスが表示されます。
インデックスを指定してデータを表示させたり、もちろん関数やメソッドを利用することもできます。
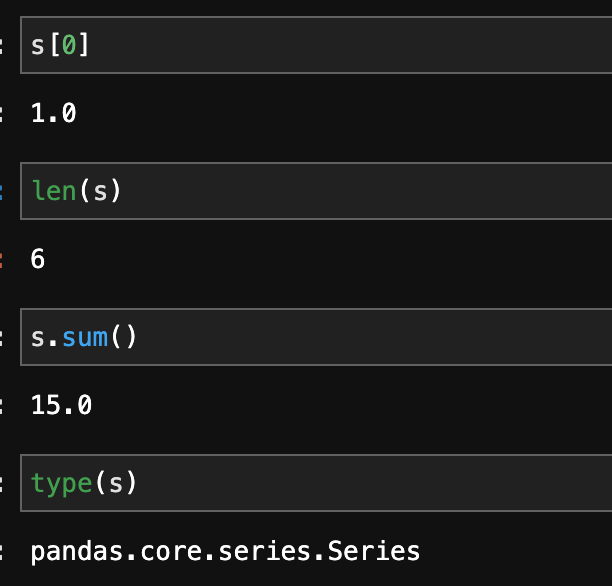
s[0]
len(s)
s.sum()
type(s)※上記のようにまとめて実行すると一番新しいものが出力されます。
ドット(.)を入力した時に[tab →|]キーを押せば、使用できるメソッドの一覧が表示されます。
2次元のデータをDataFrame()で作成
次は2次元のデータを作ってみましょう!DataFrameの方が活用する機会が多いかもしれません。DataFrame()を使って2次元のデータを作成できます。
リスト型データを使った場合は下記のようになります。
d =[['1','2','3'],[1,2,3]]
df = pd.DataFrame(d)
df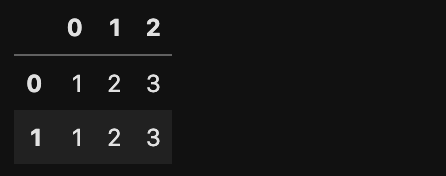
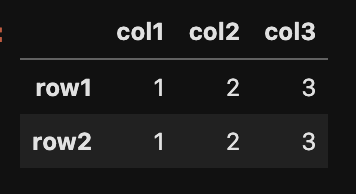
行と列名はそれぞれ名称の変更が可能です。 下記のような設定します。
d =[['1','2','3'],[1,2,3]]
df = pd.DataFrame(d,
index=["row1","row2"],
columns=["col1","col2","col3"])
df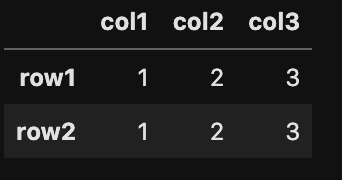
辞書型データを使っても作ることができます。
df = pd.DataFrame({'col1': [1, 1], 'col2': [2, 2],'col3':[3, 3]},
index=['row1','row2']
)
dfDataFrameを使う際は変数をdfにすることが多いです。
データのタイプは次のようにして確認できます。
df.dtypes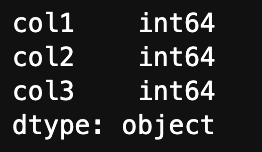
データのタイプを調べるとint(数値)であることがわかります。
DataFrame()を操作してみよう
DataFrame()を使った2次元のデータの作り方は見てきました。本来の扱うデータはもっとデータ量も多く、複雑なので整理は必須になると思います。
ここからはDataFrame()の基本操作を一通り見ていこうと思います!
まずはデータを準備する必要があるので、10行5列のデータをrandomを使って作ってみます。
df = pd.DataFrame(np.random.randn(10, 5))
df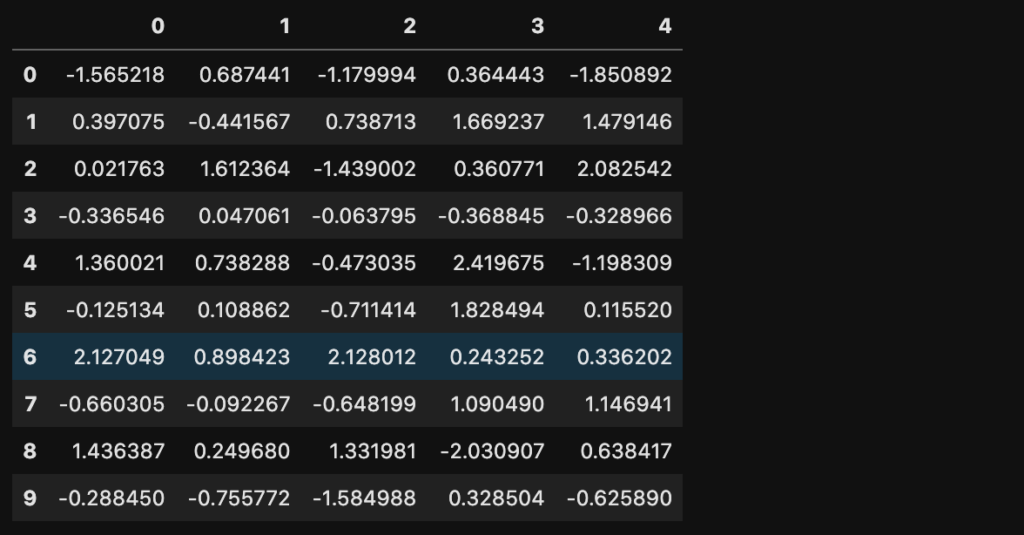
このままでは、データの項目が一体何なのか、わからないのでラベルをつけていきます。
データにラベルをつける
行と列の項目にラベルをつけていきます。
df = pd.DataFrame(np.random.randn(10, 5),
pd.date_range('20211201', periods=10),
columns=['A', 'B','C', 'D','E'])
dfdate_range()を使って列の項目にラベルをつけることができます。今回は日付を入れました。
preriodsにはデータの数を指定します。行の項目にはcolumsにリストでラベルを指定しています。
このような結果になります。
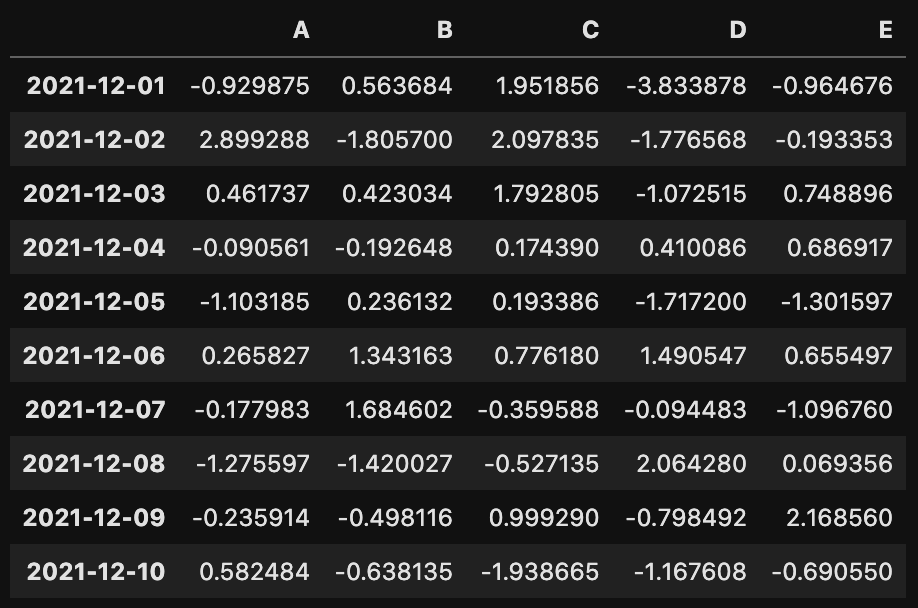
列、行それぞれの項目が表示されたので、わかりやすくなります。
ここからかく
head()でデータの先頭、tail()でデータの末尾を取得する
データの先頭行を表示するならhead()を使います。
df.head(3)上記の場合はカラム名含めて4行表示できます。df.head(0)にするカラム名の表示されます。
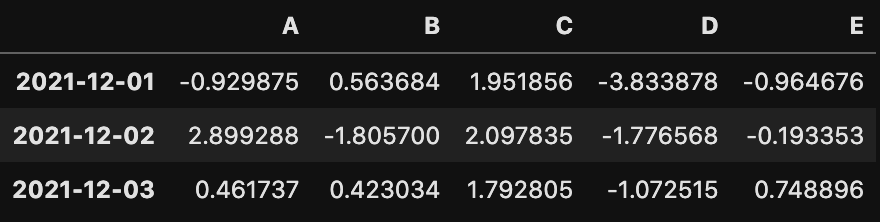
ちなみにdf.head()数字を入れない場合は、先頭から5つのデータ(カラム名含めて6行)が表示されます。
末尾のデータを表示させるならtail()を使います。
df.tail(3)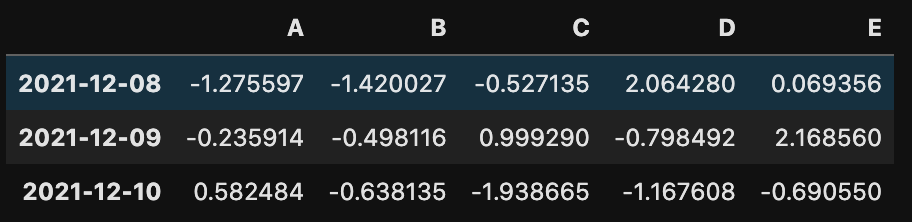
3を入れているので末尾から3つのデータを表示しています。数値を入れなければdf.head()同様に5つのデータが表示されます。
index, columns, valuesでそれぞれのデータを表示させる
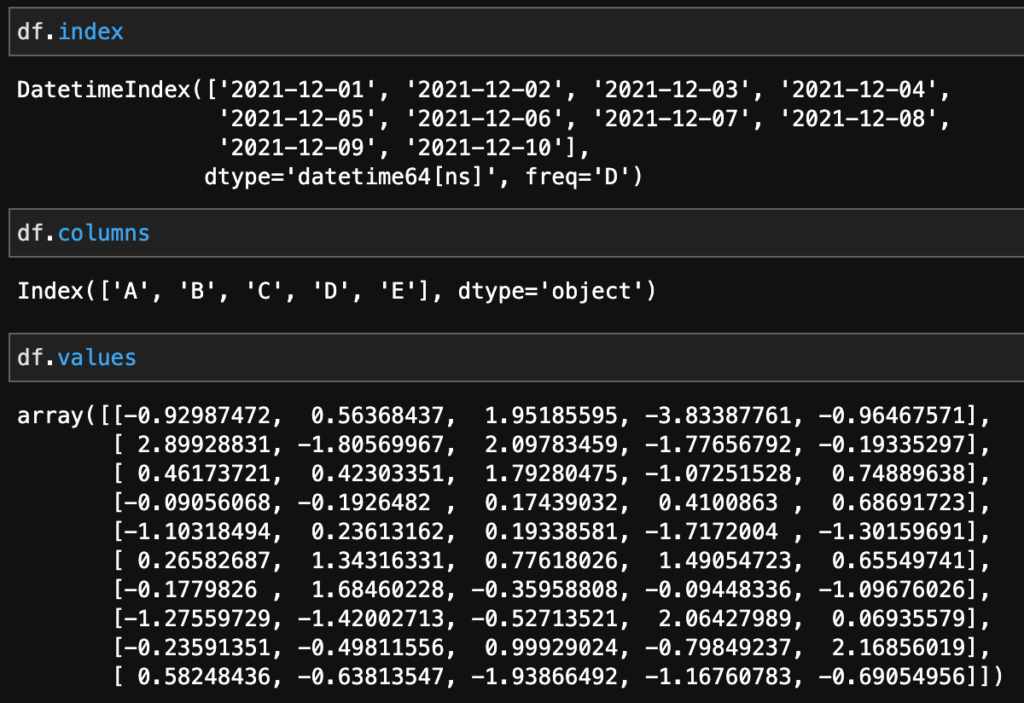
データの列の見出し(インデックス)、行の見出し(カラム)、データの値をそれぞれ表示させるためには以下のコードで表示させます。
列の見出し(インデックス)
df.index行の見出し(カラム)
df.columnsデータの値
df.valuesこのように表示されます。
describe()で要約統計量(基本統計量)を表示させる
describe()を使えば要約統計量(基本統計量)を取得できます。
df.describe()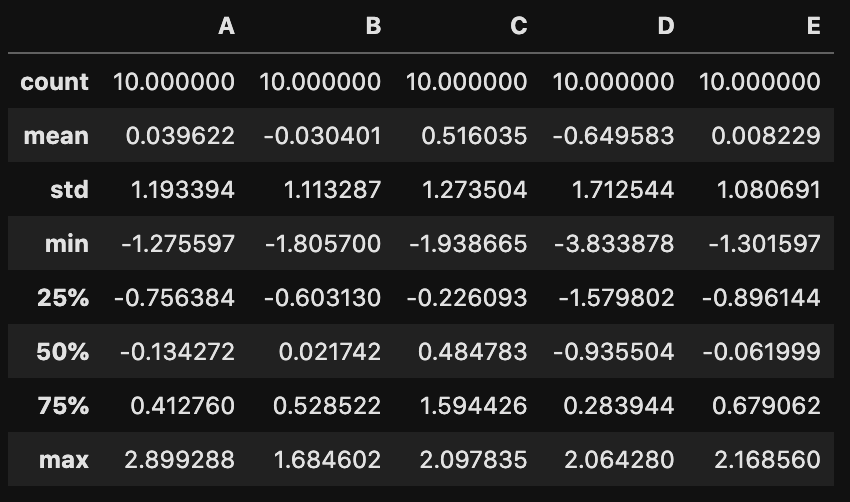
それぞれ、件数 (count)、平均値 (mean)、標準偏差 (std)、最小値(min)、第一四分位数 (25%)、中央値 (50%)、第三四分位数 (75%)、最大値 (max) が確認できます。
行と列の転換、値のソート
行と列の転換にはTを使います。
df.T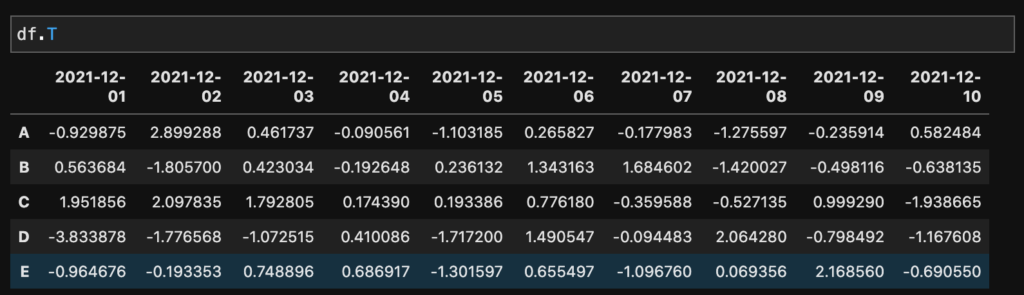
値のソートにはsort_values()を使います。
df.sort_values('C')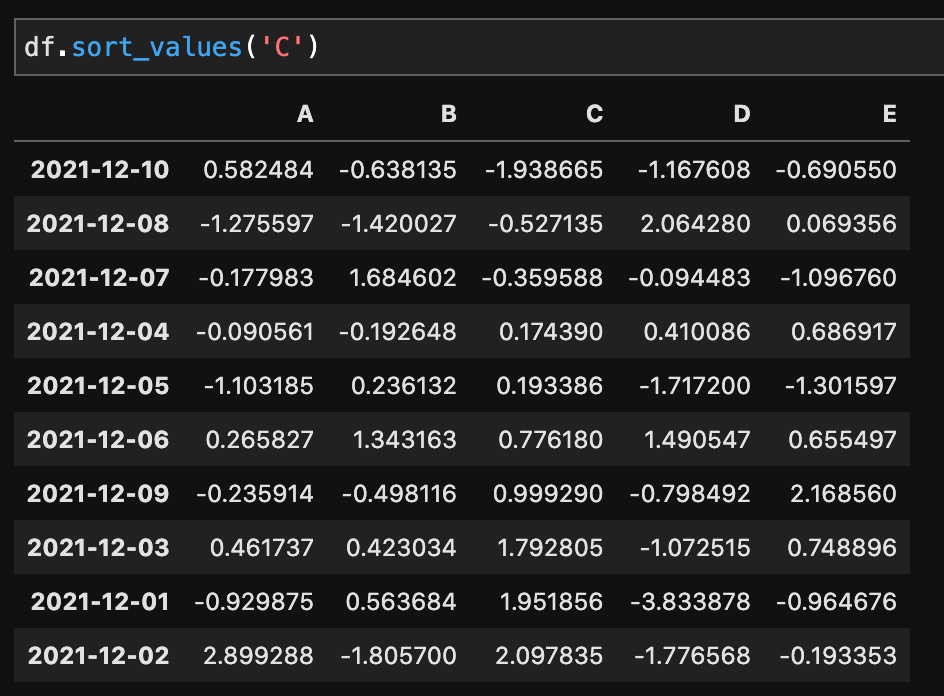
Tで縦横が変換されているのがわかります。ソートはCの項目で小さい順に並び替えられているのがわかります。
データのスライス
リストと同じように、インデックスやラベルの値を使って範囲指定してデータをスライスして表示することができます。
df[1:4]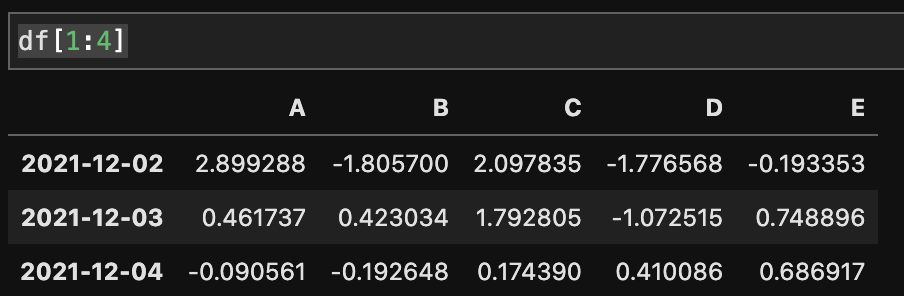
df['20211202':'20211206']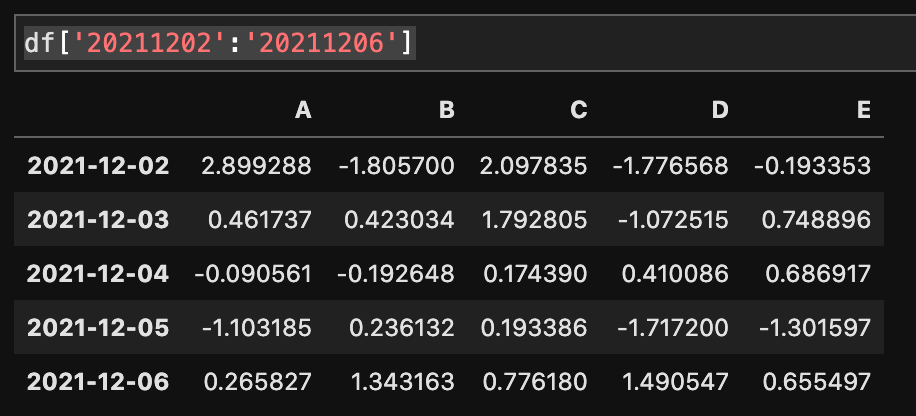
copy()と列の追加
もう一度、dfの内容を確認しておきます。
df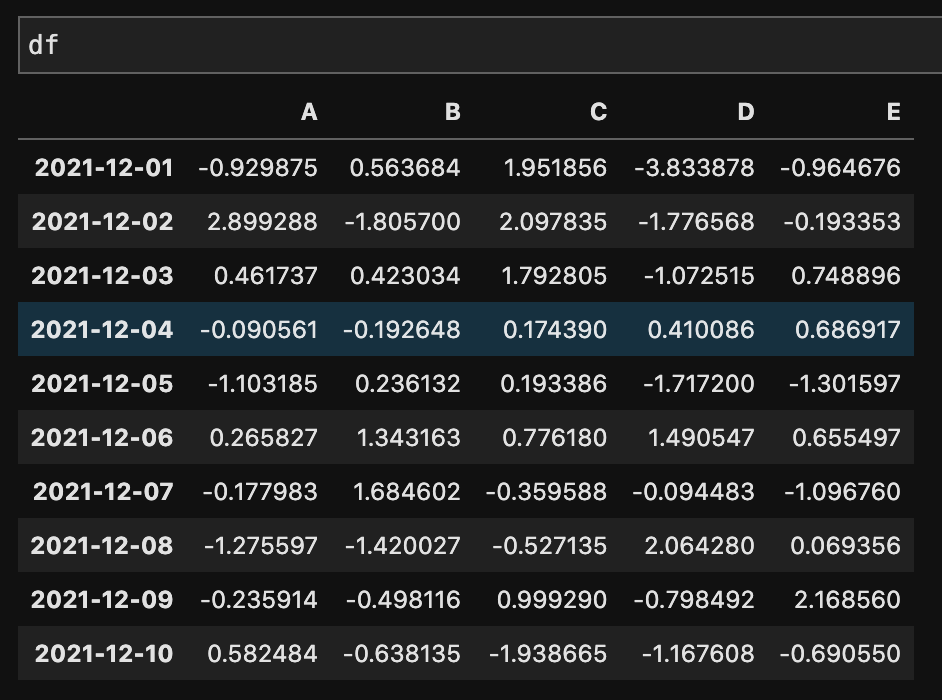
では、copy()を使ってデータをコピーして、F列を加えてデータを入れてみます。
df2 = df.copy()
df2['F'] = ['Test1', 'Test2', 'Test3', 'Test4','Test5',
'Test6', 'Test7', 'Test8', 'Test9', 'Test10']
df2copy()で複製することができます。この複製したデータの変数をdf2とします。これにF列を追加していきます。
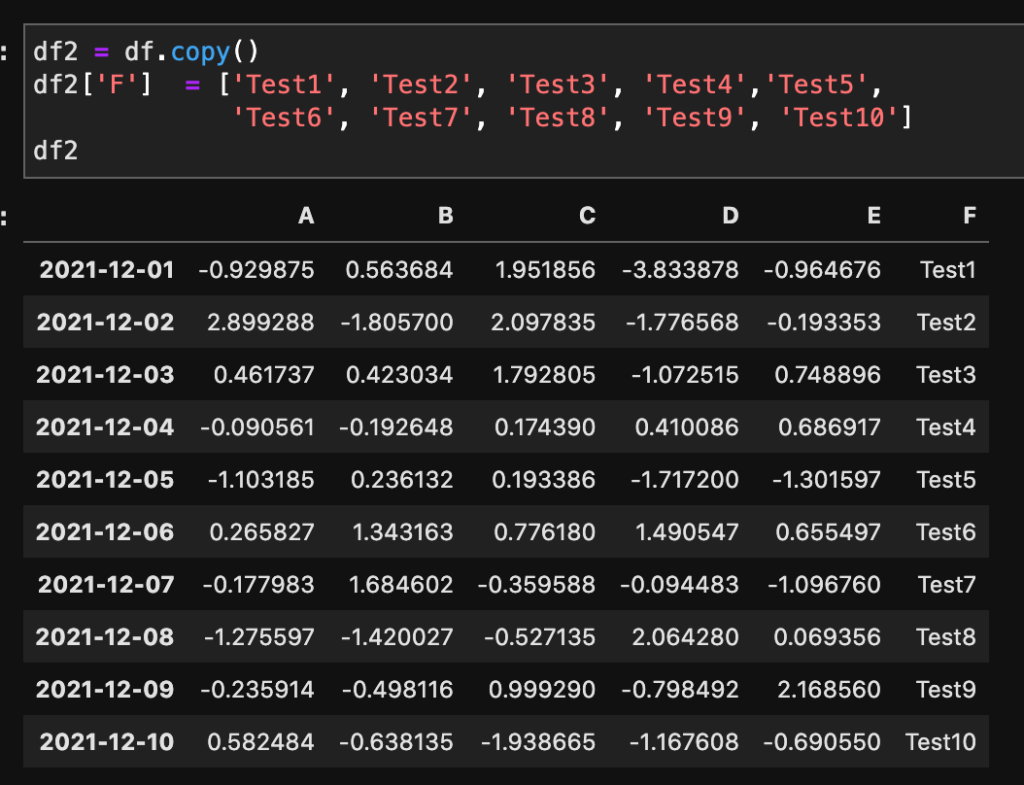
F列に値が入っているのがわかります。今回は「Test」を入れました。
isin()を使って、値が入ってる列のデータを取り出すことができます。
df2[df2['F'].isin(['Test4', 'Test9'])]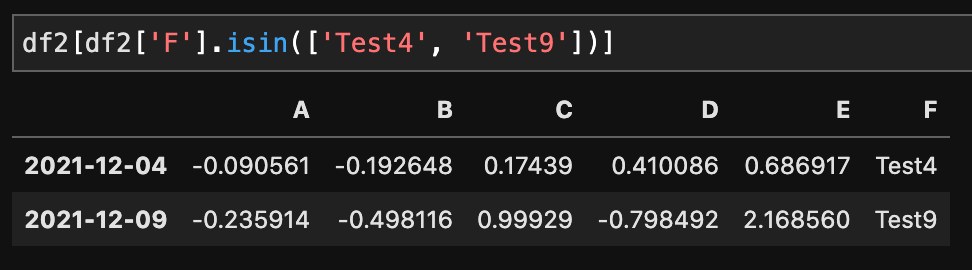
新たな1次元データを列データに加える
1次元のデータ作成し、そのデータをdf2に追加してみましょう!
s = pd.Series([1,2,3,4,5,6,7,8,9,10], index=pd.date_range('20211201', periods=10))
s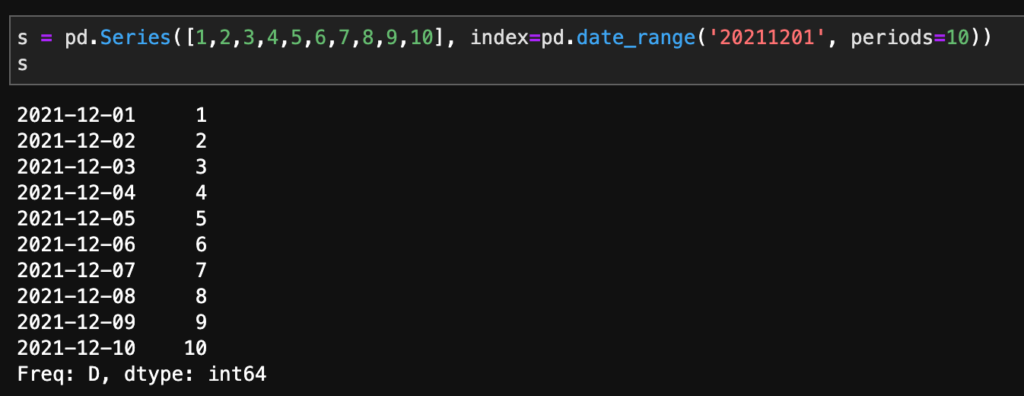
このsのデータをdf2に’G’列として加えてみましょう! 次のように行います。
df2['G'] = s
df2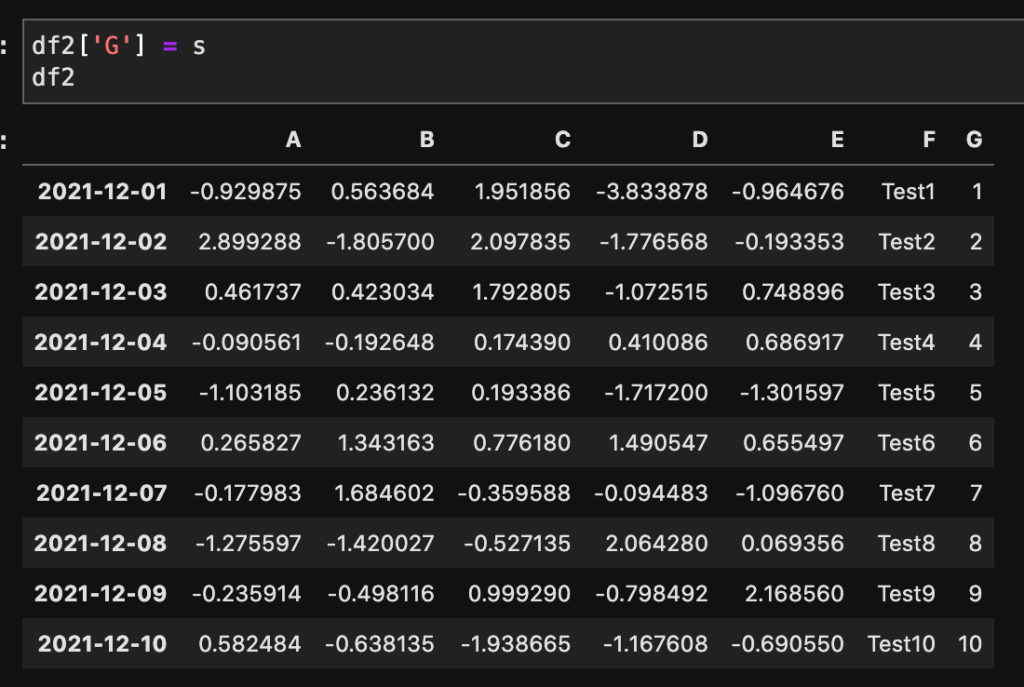
shift()でデータをシフトする
shift()を使ってデータをズラすことができます。
df.shift(1)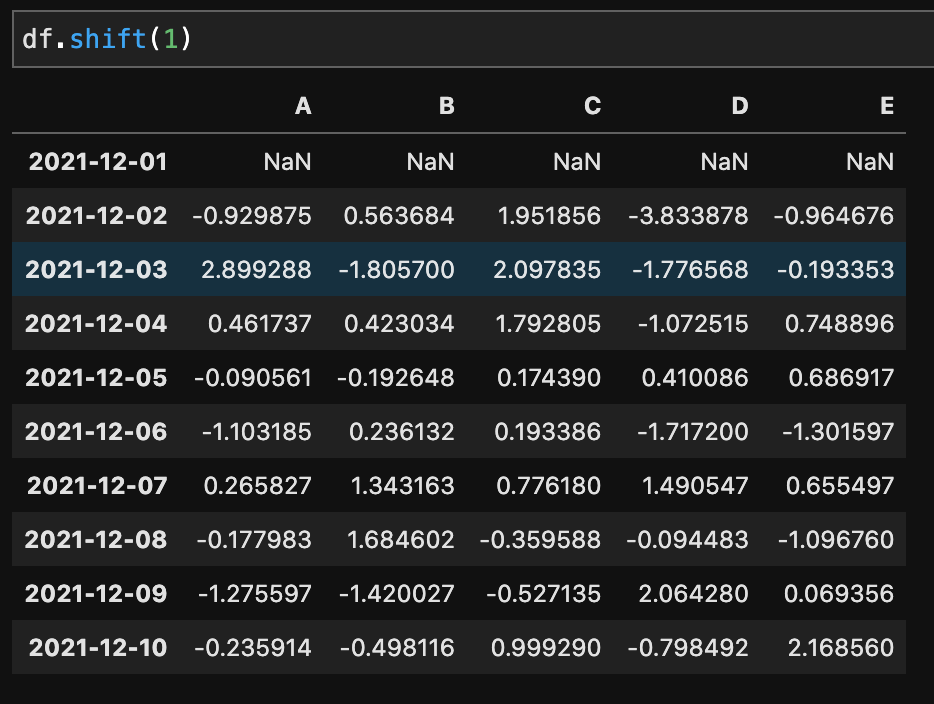
元々2021-12-01にあったデータが一つ下にズレています。 そのため、2021-12-01の行がNaNになっています。
concat()で連結する
扱いやすいように新しい小さなデータを作ります。
df = pd.DataFrame(np.random.randn(3, 4))
df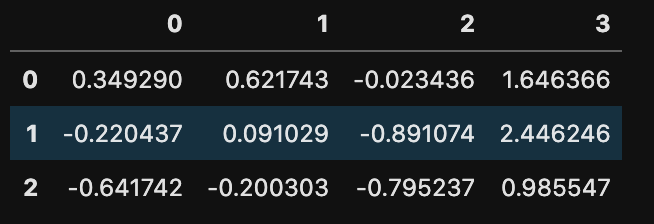
3行4列のデータを作ります。このデータを2つ連結させた新しいデータを作ってみます。
そのためには、concat()を使います。
pd.concat([df, df])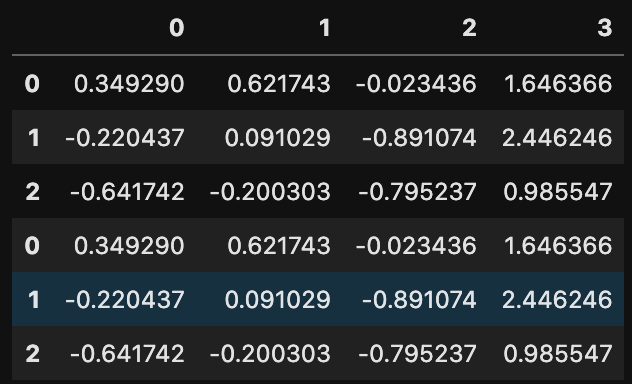
0,1,2の行を新たに増えて、連結されているのがわかります。
append()で追加する
また新たにデータを作ります。
df = pd.DataFrame(np.random.randn(2, 3), columns=['a', 'B','c'])
df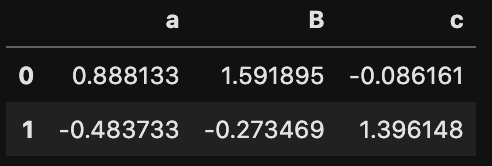
また、新しい1次元データを1つ作りこのデータをdfに追加してみます。
s = df.iloc[0]
s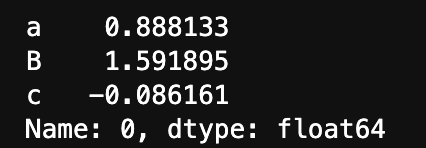
このdf2のデータを、元のdfにappend()で追加します。
df.appned(s)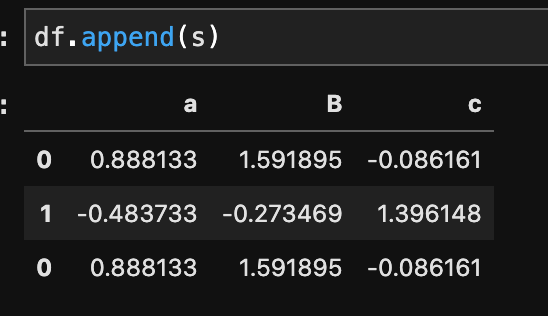
最後の行にsのデータが追加されているのがわかります。
ただ行に0が2つあってデータとして扱いにくいですよね。このような場合はignore_index=Trueとして書き直すことで、新しく追加されるデータに新しい行番号が付与されます。
df.append(s, ignore_index=True)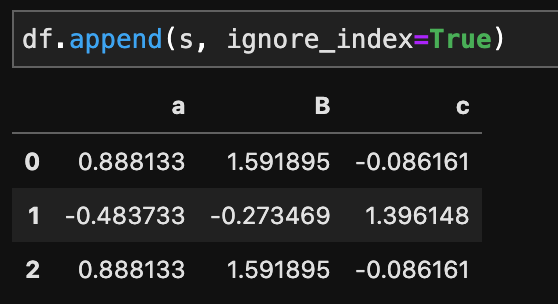
0,1,2と行番号が整えられました!
groupby()で要素をグループ化
また、新しいデータを作ります。
df = pd.DataFrame({'A': ['P', 'D', 'P', 'D'], 'B': np.random.randn(4)})
df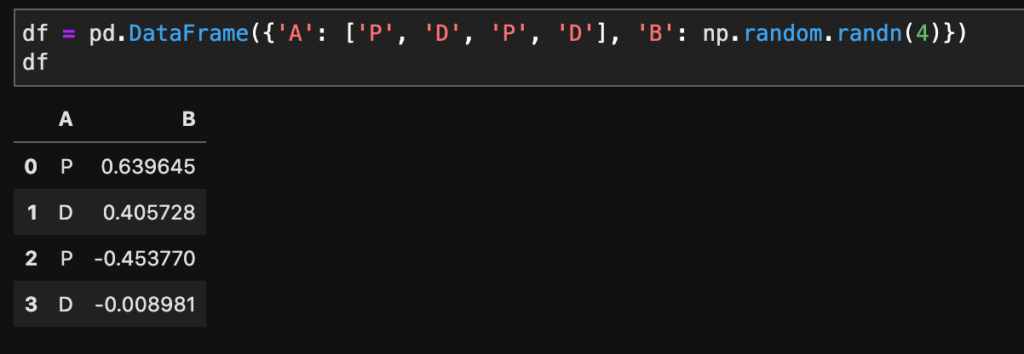
このデータには、A列のデータにP, D,がそれぞれ2つ入っています。
groupby()を使えば、同じ要素をグループ化することができます。
次のコードは要素をまとめてその要素ごとに合計します。
df.groupby('A').sum()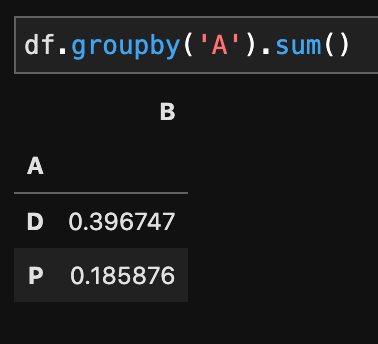
P、Dそれぞれの値がまとめられてsum()で合計されていますね! カテゴリーごとの集計などで活用します。
終わりに
いかがでしたでしょうか!
今回の記事では「Pandasの基本的な使い方」を紹介してきました!
Pandasの基本的な操作を一通り見てきましたので、これで実際のデータを扱うこともできるようになったはずです!
ちなみに、実際のデータ表からデータを取得する方法についても下の記事で紹介しているので、合わせて活用してみてください!


