

こんにちは! 今回はPandasでCSVファイルを読み込む方法を紹介します!
Pandasはデータ分析に必須のライブラリです。分析する前に必要なデータの前処理を効率的に行うことができます。なので、CSVファイルを読み込む工程はデータ分析のために必要な作業となります。
ライブラリのインストール
Pandasがインストールされていない場合はターミナルを開いて、下記のコードでインストールしましょう。
pip install pandasライブラリのインストールが完了すれば、準備OKです!
次にインポートを行います。Pandasはpdと略して活用するのが一般的になっています。as pdとすことで以降のコードではpdがpandasの役割を果たします。
import pandas as pdCSVファイルを読み込む
CSVファイルを読み込むためには read_csv を使います。
下記のような感じです。
df = pd.read_csv('ファイル名.csv')df = pd.read_csv('*****/******/ファイル名.csv')CSVファイルが同じディレクトリ内にあれば、ファイル名で読み込むことができます。同じディレクトリ内に無い場合は、ファイルの位置を示すパスを入力しましょう!

Indexのパラメータ (設定)
df = pd.read_csv('ファイル名.csv')
df = pd.read_csv('ファイル名.csv', index_col = None)csvを読み込む際に、indexを指定して読み込むことができます。 設定をしない場合はデフォルトでindex番号が付与されます。
df = pd.read_csv('ファイル名.csv', index_col=列の数字)opitionとして、index_col =列番号を指定することで、指定した列をインデックスにすることが可能です。
headerのパラメータ(設定)
df = pd.read_csv('sample.csv',names=['name', 'adress', 'tel'])データを読み込む際に画像のようにheaderがない場合があります。そんな時はデータを読み込む時にheaderの設定を行いましょう。
設定をしないとデータがカラム名のようになってしまいます。

df = pd.read_csv('ファイル名.csv',header=None)カラム名(列名)は特に必要ない場合などはheader=Noneで設定すると図のように列名に数字を付与することも可能です。
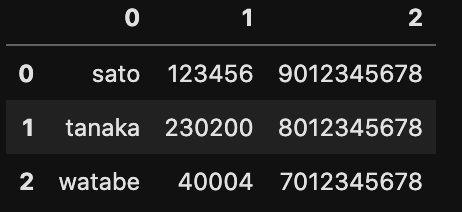
日本語データの読み込みパラメータ(設定)
df = pd.read_csv('ファイル名.csv', encoding='shift-jis')
df = pd.read_csv('ファイル名.csv', encoding='cp932')日本語のデータを読み込む際はencodingにshift-jisやcp932を設定する必要があります。encodingを設定しないとエラーで読み込めません。 どちらも日本語に対応させることができます。
cp932は㍻や№などの拡張文字にも対応しているので、拡張文字がデータで使われている場合はencoding=’cp932′で設定しましょう。
郵便番号や電話番号のデータを読み込むパラメータ(設定)
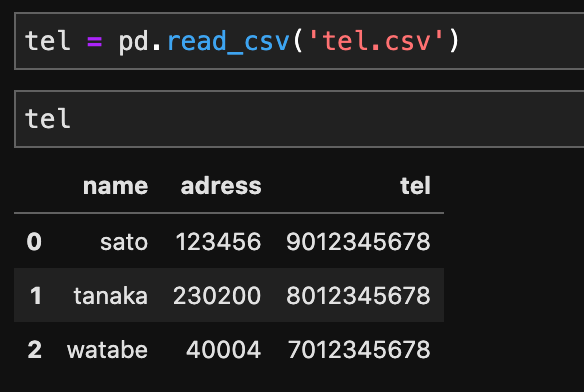
df = pd.read_csv('ファイル名.csv',dtype={'カラム名': object})電話番号や郵便番号などで、0から始まる数字の列を読み込む際にも、設定が必要です。
設定をせずにデータを読み込むと下記の例のようにtelの「090、080、070」の0が勝手に削除されて、読み込まれています。
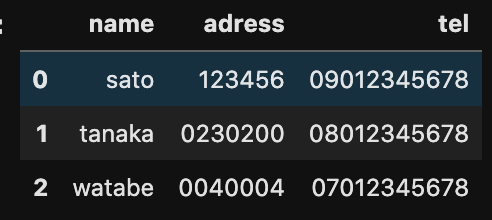
tel = pd.read_csv('tel.csv',dtype={'adress': object, 'tel': object})dtype={‘adress’: object, ‘tel’: object}この設定で、住所と電話番号のデータ型を数字からオブジェクトに変更することで、0が勝手に消えないようにしてデータを取り込むことができます。
このように、0が消えずに取り込めています。
列を指定して読み込むパラメータ(設定)
df = pd.read_csv('ファイル名.csv',usecols=['カラム名'])
df = pd.read_csv('ファイル名.csv',usecols=[カラム番号])カラム(列)を指定してデータを読み込むことも可能です。その場合はusecols=[‘カラム名’]or[‘カラム番号’]で列の指定ができます。
#カラム名orカラム番号で抽出が可能。
tel = pd.read_csv('tel.csv',usecols=['tel'],dtype={'tel': object})
tel = pd.read_csv('tel.csv',usecols=[2],dtype={'tel': object})実際にtelのカラム(列)のデータのみ抽出することができました。

読み込まない行のパラメータ(設定)
df =pd.read_csv('ファイル名.csv',skiprows=[行の番号])skiprowsで読み込まない行を設定することができる。
skiprows = 2(数字のみの場合は先頭から指定した行を読み込まない)
skiprows = [1]([ ]で囲うと数字の行を読み込まない。[1,2]のように複数の行を指定することもできる。)
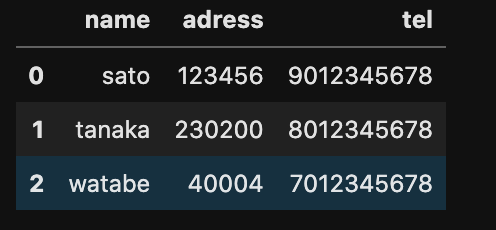
設定なく、データを読み込むと上記のようなデータとなる場合に1行目のデータ(name = sato)を読み込まないと下記のようになる。
tel =pd.read_csv('tel.csv',skiprows=[1])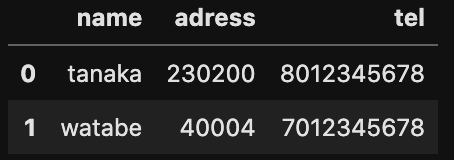
末尾のデータを読み込まないパラメータ(設定)
df =pd.read_csv('ファイル名.csv',skipfooter=1)読み込むデータの末尾の行に合計の数値がある場合などはその行を消す必要があるため、skipfooter=1で行を消す。
先頭から指定した行までのデータを読み取るパラメータ(設定)
df =pd.read_csv('ファイル名.csv',nrows=行の番号)nrowsで先頭から指定した行までのデータを読み込むことできる。
tel =pd.read_csv('tel.csv',nrows=2)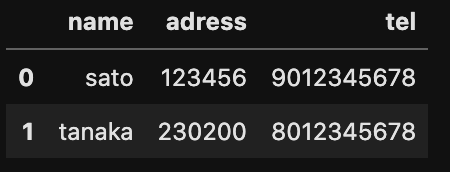
終わり
いかがでしたでしょうか!
今回はPandasでCSVファイルを読み込む方法について紹介してきました!
パラメータ(設定)を使うことで、必要なデータのみを読み込むことができます。
色々、挑戦してみてください!
また、他の記事で会いましょう〜!
Pythonやデータ分析をもっと学びたい方へのおすすめのスクールがあります。
データ分析をがっつり学べるおすすめのプログラミングスクールはAidemyです!
なぜ、Aidemyがおすすめなのか記事で徹底解説しています!

スクール以外のおすすめの学習方法はUdemyです!
私が実際に学んだおすすめの講座を紹介している記事を参考になさってみてください。


