

こんにちは! 【文系・非エンジニア】マーケターのNocky(のっきー)です!
今回はPythonでデータ分析するために必須のライブラリである【Pandas】でデータを取り出す方法についてご紹介します。初学者の方にも学べるように、噛み砕いてテーマについて、紹介していきます。
実際に手を動かして、挑戦してみてください! Google Colaboratoryを使えば、環境設定することなく、Pythonを使うことができます。
今回の記事によって下記について紹介します。
DateFrameから行列を指定してデータを取得する
条件を指定してデータを取得する
データ分析のする前に、データを自在に扱えるようになる必要があります。その前段として求めるデータを取り出す方法を紹介します。
抽出するデータについて
import pandas as pd
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
df = pd.DataFrame(housing.data, columns=housing.feature_names)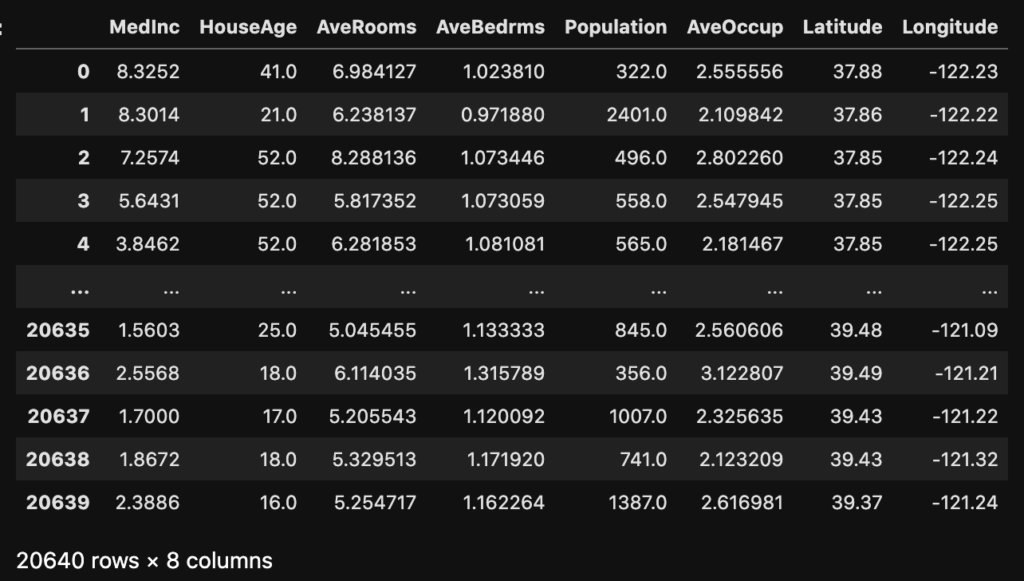
scikit-learn(機械学習のライブラリ)のサンプルデータセットであるカリフォルニアの住宅価格を使って行います。
データセットの大まかな内容はこちらです。
(MedInc):収入の中央値
(HouseAge):ブロック内の家の中央年齢
(AveRooms):平均部屋数
(AveBedrms):ベッドルームの平均数
(Population):ブロック人口
(AveOccup):平均住宅占有率
(Latitude):家屋の緯度
(Longitude):ハウスブロックの経度
scikit-learnがインストールされてない方は 「pip install scikit-learn」ターミナルでインストールしましょう。
pip install scikit-learnそれでは、データの取り出し方を見ていきましょう!
データ分析する場合も全てのデータを使って分析することはほぼほぼ、ありません。(まだ、出会ったことがないだけかも。。)データの中から一部分の必要なデータを取り出し、分析を行っていきます。
このため、DataFrameから必要な部分を取り出すという操作は必ず発生します。
必要な列のデータを取り出す方法
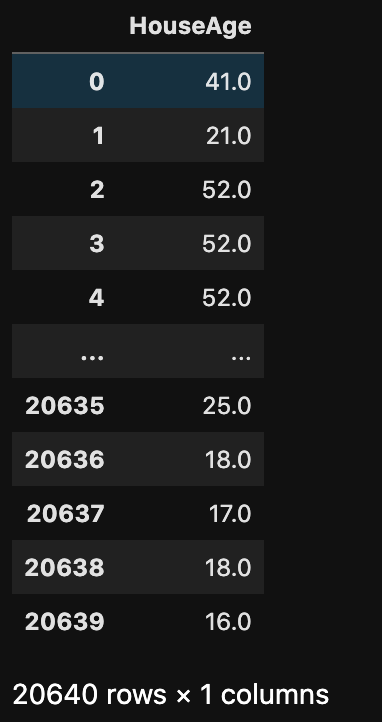
まずは指定した列だけを取り出してみましょう。今回は、”HouseAge”列を取り出す場合でみてみましょう。
df[["HouseAge"]]というように、“HouseAge”の列名で指定します。するとこのように“HouseAge”の列のみ取り出すことができます。
複数の列を指定する場合は下記のようになります。
df[["HouseAge","Population"]]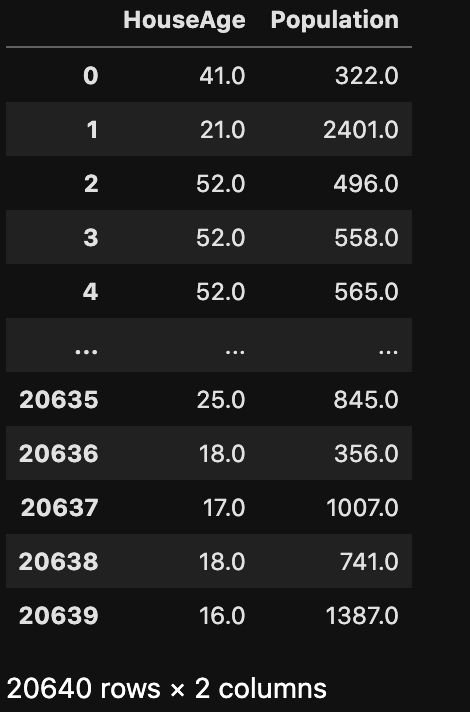
ちゃんと列取り出すことができました! データを取り出す時に[ ]が2つが必要なのには理由があります。
[ ]を1つ場合、DataFrameとしては結果を返してくれません。
df["HouseAge"]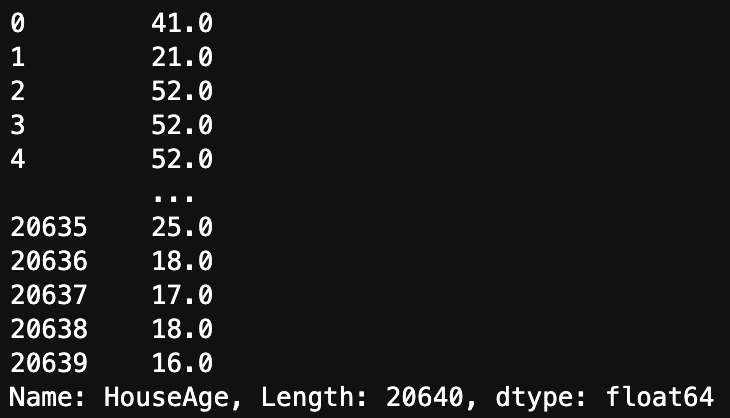
[ ]を1つ場合、先ほどとは違うSeriesと呼ばれるデータ構造で取り出されます。
Seriesはnumpyのndarrayと非常によく似た構造で、互換性を持っています。
numpyを使って演算処理をするときにはこのデータ構造にすることで、スムーズに演算処理ができるようになると思っていると良いでしょう!
必要な行のデータを取り出す方法
次は、必要な行のデータを取り出す方法を見ていきましょう。
行を指定する場合は、インデックスを用います。インデックスは、各行のデータのかたまりを識別する数字のことです。
dfの場合、左にある0~20639までの数字がインデックスにあたります。
インデックスを使って行を取り出すことができます。行を指定するときは、コロン(:)を使います。
df[0:10]インデックス番号の1から9(10のデータは含まない)までのデータを取り出すことができます。
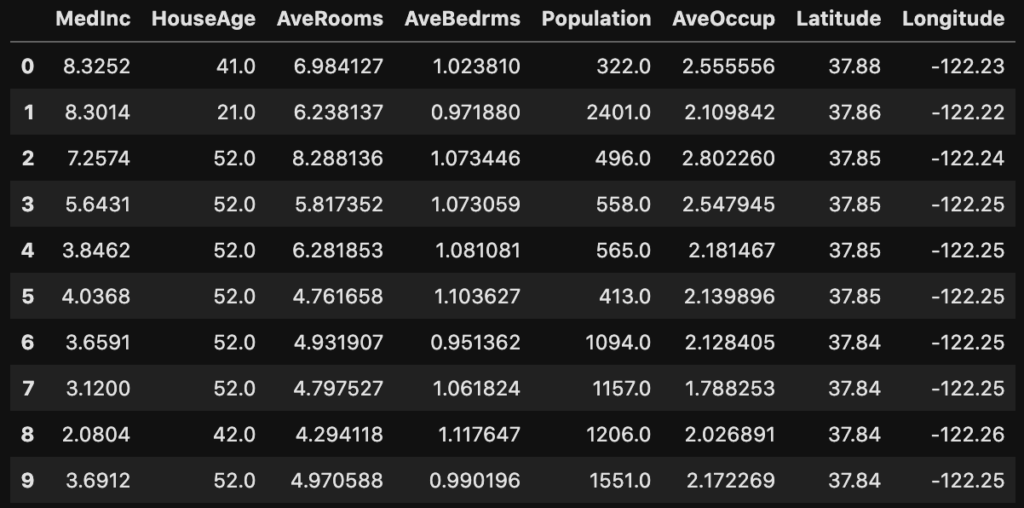
インデックスは0から始まります!
必要な行、列のデータを取り出す方法
行と列の両方指定して取り出したい場合はlocを使います。(ほとんどそうですよねw)
たとえば、”HouseAge”列と”Population”列の1~9行目(インデックス番号0~9)を取り出す場合は下記のようになります。
df.loc[0:10,["HouseAge","Population"]]locの[ ] の中は、[行を指定 , 列を指定]という順番で条件を指定します。
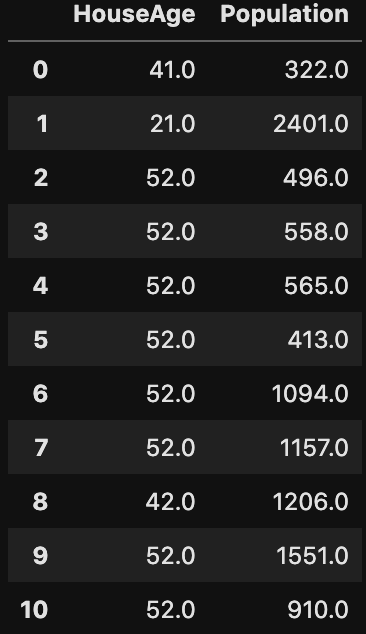
ちなみにインデックスの0から取り出す場合は0を省略することができます。逆に:以降にインデックスを指定しなければ、インデックスの最後の番号までを取り出します。
df.loc[:10,["HouseAge","Population"]]
df.loc[20630:,["HouseAge","Population"]]データの位置を指定してデータを取り出す方法
データの位置を数字で指定してデータを取り出す方法を紹介します。
データの位置を数字で指定してデータを取り出すためにはilocを使います。ilocを使うことで、何列目、何行目のでデータを取り出すことができます。
df.iloc[:10, 5:8]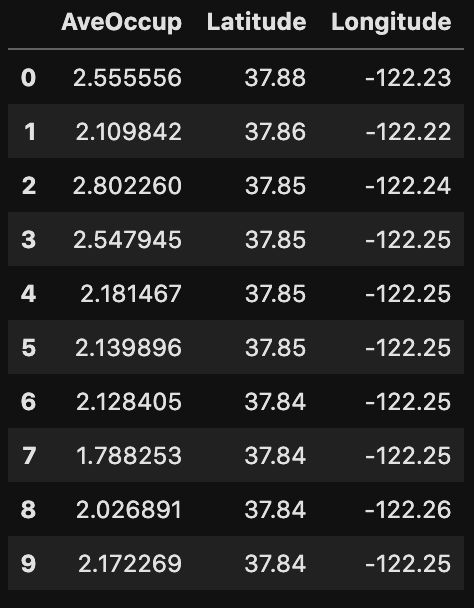
例のように10行目までのデータの5、6、7列目のデータを取得しました。
数字の指定はややこしいので、実行して求めるデータが得られているか確認することをお勧めします。
条件を指定して、データを取り出す方法
DataFrame上の位置ではなくて、指定の条件を満たすものだけを取り出すことも可能です。
たとえば、平均部屋数が7室以上のデータだけ取り出したい場合は、
このように条件を設定する。
df.loc[df["AveRooms"] >= 7]条件を付けてデータを取り出すためには、locを使います。
行指定の部分に条件式を入れることで、条件に該当するデータだけ取り出すことができます。
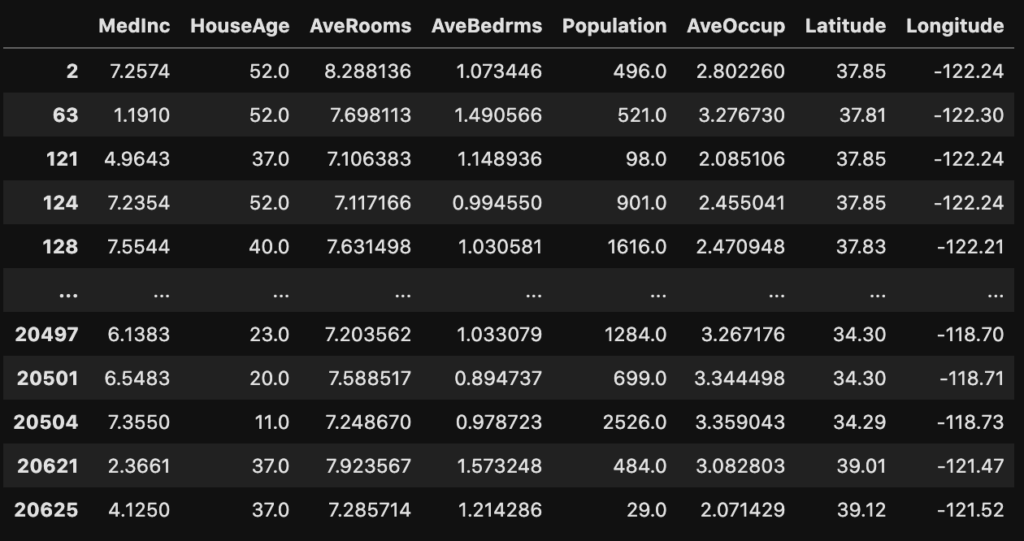
AveRoomsが7部屋以上のものばかりになっています。
複数条件でデータを取り出す方法
複数の条件を指定することもできます。
例えば、『平均部屋数が7室以上かつPopulationが100以下』のデータを指定したい場合、下記のように条件式を ()でくくり、論理演算子でつなぎます。
df.loc[(df["AveRooms"] >= 7)&(df["Population"] <= 100)]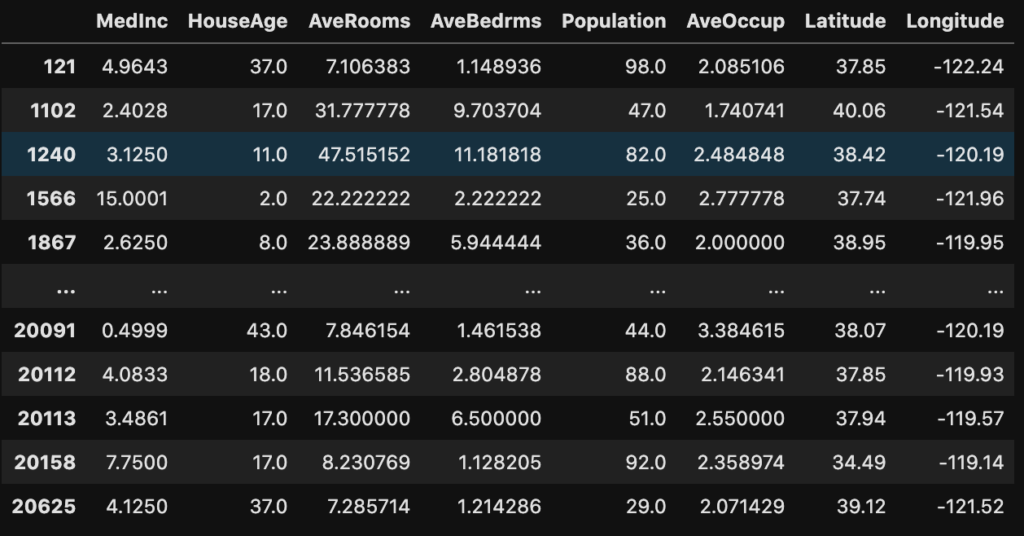
平均部屋数は7室以上で人口が100以下なので、落ち着いた地域の平均7室以上の大きめな家を抽出することができました。相当絞ることができました。
『平均部屋数が7室以上またはPopulationが100以下』という条件の場合、下記のように条件式を ()でくくり、|でつなぎます。
df.loc[(df["AveRooms"] >= 7)|(df["Population"] <= 100)]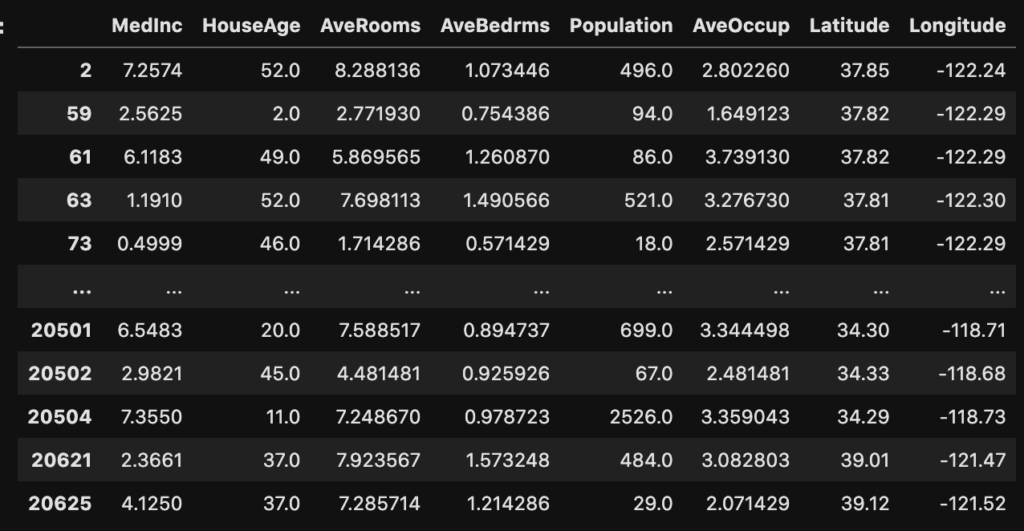
このようにまたは条件で検索できています。
終わり
いかがだったでしょうか!
今回は【Pandas】でデータを取り出す方法についてご紹介しました。
データ分析を行うためにPandasでのデータを取り出すスキルは必須です!
Google Colaboratoryなど使うなどして、実際に手を動かし、データを検索を試してみてください!
今後もPandasについて、記事化していきます!
お付き合いいただき、ありがとうございました!
また、他の記事でお会いしましょう〜!
おすすめ記事



